
못정함
[BDA x 영진닷컴] BDA 스터디: 2주차 / PART 3 데이터 분석 - 정형 데이터 마이닝(p201~p244) 개념 정리 본문
[BDA x 영진닷컴] BDA 스터디: 2주차 / PART 3 데이터 분석 - 정형 데이터 마이닝(p201~p244) 개념 정리
hadara 2024. 4. 4. 22:3024년 4월 3일 ADsP 2주차 스터디를 진행했다.
스터디 범위: PART 3 데이터 분석 - 정형 데이터 마이닝(p201~p244)
이번 주는 온라인으로 진행했고, 스터디원들과 PART 3를 정리하며 서로 모르는 부분을 질문하는 시간을 가졌다. 다음 주에 단원 마무리하며 문제를 함께 풀어볼 계획
공부, 스터디를 하다보니 분류분석이 다른 파트에 비해 어려웠기 때문에 양도 많아서.. 이 부분은 꼭 여러번 복습해야 되겠다고 느꼈다.

미완성으로 남을 수도 있지만....개념 정리
데이터마이닝 개요
-통계분석은 가설이나 가정에 따른 분석이나 검증을 하지만 / 데이터마이닝은 다양한 알고리즘을 이용해 DB의 데이터로부터 의미있는 정보를 찾아내는 것. (의사결정에 활용)
-5단계: 목적 설정 -> 데이터 준비 -> 데이터 가공 -> 데이터 마이닝 기법 적용 -> 검증
ML algorithm
| 지도학습 | 비지도학습 |
| 의사결정 나무, 인공신경망, 일반화 선형 모형, 회귀분석, 로지스틱 회귀분석, 사례기반 추론, 최근접 이웃법(KNN), 지지벡터기계(SVM) | OLAP, 연관분석, 군집분석(K-Means Clustering), 자기조직화지도(SOM) |
*지도학습: data에 대한 label(명시적 정답)을 제공하고 컴퓨터에 학습시킴 (data, label) 형태로 학습
*비지도학습: label 없이 컴퓨터를 학습시킴
section1. 분류분석
-범주형 속성의 값을 알아맞히는 것. 각 그룹이 정의되어 있음. 지도학습임
1) 로지스틱 회귀 모형
-독립변수: 수치형 / 종속변수: 범주형 (2가지 값만 가짐. 성공/실패, 참/거짓, 사망/생존 등)
-R에서는 glm() 함수 활용
-유의성 검증: 표본자료를 통해 모집단 값에 대한 주장을 평가하는 방법. 카이제곱 검정을 활용
-독립변수가 주어질 때 종속변수의 각 범주에 속할 확률이 얼마인지를 추정하여 분류하는 목적으로 활용
원리)
독립변수를 x, 종속변수를 z로 표기한다면 로지스틱 회귀 모델식은 z = wx + b . z 값의 범위를 [0,1]로 만들어야함 (z 값의 범위를 변환해주는 것이 시그모이드 함수)
▶ 시그모이드 함수: S자형 곡선을 갖는 함수. -∞ ~ + ∞의 범위로 입력되는 값을 0~1 사이의 값으로 변환
▶ 오즈비 (승산비, Odds Ratio)
-특정 사건이 발생할 확률과 사건이 발생하지 않을 확률에 대한 비율
p / 1-p (성공활률/실패확률)
▶ 로짓(logit) 변환: 오즈에 로그를 취한 함수. (입력값의 범위 0~1일 때, 출력 값으로 -∞ ~ +∞로 변환)
2) 인공신경망(ANN, Artificial Neural Network)
-인간의 뇌 구조를 기반으로한 추론 모델 / 입력층, 은닉층, 출력층(여기에 활성화 함수 적용, 오직 하나의 출력 신호) 으로 구성. 각각의 층에는 뉴런이 여러 개 포함됨.
-각 뉴런은 가중치(weight)가 있는 링크로 연결되어있음. 가중치를 조절하는 학습 알고리즘임.
-복잡한 비선형 관계에서도 사용 / 이상치 잡음에 민감하게 반응하지 않음.
학습)
-가중치 변수를 초기화하고 훈련 데이터를 통해 학습하는 과정에서 반복적으로 조정(갱신)해나간다
-뉴런은 링크로 연결되어있고, 각 링크에는 수치적인 가중치 변수가 존재
-은닉층 노드가 너무 많으면 과적합(Overfitting)에 빠짐 / 너무 적으면 과소적합(Underfitting) 문제가 발생
-경사하강법(Gradient Descent): 최적의 모델을 생성하기 위해~ 모델의 기울기가 낮은 방향으로 계속 이동시켜가며 가중치 변수가 최적의 값에 이를 때까지 반복. 역전파 알고리즘으로 (출력층 -> 입력층) 오차 전파
활성화함수(Activation Function)
결과를 내보낼 때 (출력층) 사용 / 비선형 활성화 함수를 주로 사용
| 함수 | 특징 |
| 계단함수 (Step) | -선형 활성화함수 -입력값이 양수일 때는 1 / 음수일 때는 0을 출력 |
| 리키렐루 함수 (Leaky ReLU) | -비선형 -x > 0 -> x -x<=0 -> 0.1x 를 출력 |
| 시그모이드 함수 (Sigmoid) | -비선형 -입력값을 0~1 사이의 값으로 출력 -기울기 소실 문제 발생 |
| 소프트맥스 함수 (Softmax) | -비선형 -다중분류 -출력값을 확률로 변환 |
| 렐루 함수 (ReLU) | -비선형 -입력값이 음수면 0 / 양수면 양수값 그대로 출력 |
| 쌍곡탄젠트 함수 (Hyperbolic Tangent) | -비선형 -시그모이드와 유사 -입력값을 -1 ~ +1 사이의 값으로 출력 |
기울기 소실 문제
-역전파 알고리즘이 출력층에서 입력층으로 갈수록 기울기가 점점 작아져 0에 수렴하게 되면서 가중치가 업데이트 되지 않는 현상 (시그모이드 함수 사용 시 발생 -> ReLU, Leaky ReLU 등 다른 함수 사용하여 해결)
*신경망 모델 학습 모드
온라인 학습 모드: 관측값을 순차적으로 입력. 가중치 변수값을 매번 업데이트. 속도 빠름. 데이터 비정상성일 때 좋음
확률적 학습 모드: 관측값을 랜덤하게 입력하여 가중치 변수값을 매번 업데이트
배치 학습 모드: 전체 데이터를 동시에 입력하여 학습
순전파(Feed Foward) / 역전파(Backward)
이진분류: sigmoid / 다중분류: softmax
오차가 나오면 오차를 줄이기 위해 경사 하강법으로 역전파 과정을 수행하며 가중치 변수들을 업데이트함
경사하강법
가중치, 편향에 대한 cost 함수 그래프에서 편미분을 통해............... 암튼 오차 줄이는 과정 !
3) 의사결정나무 모형
-다중공선성 영향X / (깊을수록) 과적합 가능성 높음 / 분류, 회귀 둘 다 사용가능 -> CART(Classification And Regression Tree) 알고리즘. / (범주형, 연속 수치형에 모두)
-마디는 노드라고함. 나무의 줄기와 잎 구조로 나타내어 여러 개의 소집단으로 분류 또는 예측
-부모 마디보다 자식 마디의 순수도가 증가하도록 형성해야함. 아래로 내려갈수록 불순도 감수.
분석 과정) 변수 선택(독립/종속) -> 의사결정나무 생성(분리규칙 및 정지규칙을 바탕으로) -> 가지치기 (불필요한 노드 제거, 모델 단순화, 과적합 방지) -> 모델 평가 -> 분류 및 예측
분리 기준) 종속 변수에 대한 각 종류별 구별 정도는 순수도 또는 불순도로 나타냄 / 종속변수가 이산형인 경우 분리 기준으로 주로 불순도를 활용
4) 의사결정나무 알고리즘
-모두 하향식 접근 방법
| 알고리즘 | 이산형 목표변수 (분류나무) | 연속형 목표변수 (회귀나무) | 특징 |
| CART | 지니지수 | 분산 감소량 | |
| C5.0 | 엔트로피지수 | 엔트로피지수 | |
| CHAID | 카이제곱 통계량 | ANOVA F-통계량 | 입력 변수가 반드시 범주형 |
5) 불순도의 여러 가지 측정방법
-불순도는 분류기준값의 선택에 영향을 미침.
-해당 범주 안에 서로 다른 data가 얼마나 섞여있는지
| 엔트로피 | 정보 획득 | 지니계수 (Gini Index) | 카이제곱 |
| -무질서한 정도를 나타내는 지표 -작을수록 질서 있음 = 순수도 높음 = 불순도 낮음 -동일한 성질의 데이터끼리 잘 분류되었다는 의미임 |
-클수록 좋음 (불확실성 감소) -정보획득량 = 사전 엔트로피(불확실성) - 사후 엔트로피(불확실성) |
-작을수록 불순도 낮음 -얼마나 많은 데이터들이 섞여있는지를 나타내는 불확실성 -0~0.5의 값 -0 = 불확실성이 0 -0.5 = 최대, 데이터가 반반씩 섞여있음 -엔트로피보다 속도 빠름 |
-독립성 검증을 위해 사용 -상관간계가 가장 적도록 나눔 |
*분류 의사결정나무는 정보 획득량 (분류 전 엔트로피 - 분류 후 엔트로피)을 최대로 하는 방향으로 학습이 진행됨
*지니지수 계산
● ○ ○ ○ ○
1 - {(1/5)^2 + (4/5)^2} = 0.32
6) 앙상블 기법
-여러 개의 예측모형을 만든 후 예측모형들을 조합하여 하나의 최종 예측모형을 만드는 방법.
-각 모델의 성능을 종합하므로 전반적으로 오류 감소, 편향(Bias) 감소, 분산(Variance) 감소, 과적합 감소
종류)
| 종류 | 설명 | 참고 |
| 보팅 (voting) |
-서로 다른 여러개의 알고리즘 분류기 사용 -각 모델의 결과를 취합해 높은 확률로 나온 것을 최정적으로 결정 |
|
| 배깅 (Bagging) |
-같은 알고리즘 분류기에 서로 다른 훈련 데이터를 샘플 자료로 결합 -여러 모델이 병렬로 학습하여 그 결과를 집계 -가지칙기 X, 최대로 성장한 의사결정나무를 사용 |
-원본 데이터셋으로부터 크기가 같은 표본을 여러 번 단순 무작위추출 , 표본에 대한 복원(부트스트랩) 및 모델을 생성 -반복 추출 방법 |
| 부스팅 (Boosting) |
-예측력이 약한 모형들을 결합해 강한 예측 모형을 만듦 -여러 모델이 순차적으로 학습 |
-배깅과 유사하지만... -부트스트랩 표본을 구성하는 재샘플링 과정에서 오차가 높은 데이터에 더 큰 가중치를 주어 표본을 추출 |
| 스태킹 (Stacking) |
-개별적인 여러 알고리즘을 서로 결합 (배깅, 부스팅과 비슷) -개별 모델을 통해 한 번 예측하고 그 예측한 결과를 다시 학습 데이터와 테스트 데이터로 나누어 다시 예측한다는 차이점 |
|
| 랜덤 포레스트 (Random Forest) |
-배깅 + 랜덤 -여러 개의 의사결정 나무를 사용해 매번 분할을 수행할 때마다 설명변수의 일부분만을 고려해 과적합 문제를 피함 |
-더 많은 무작위성을 주어 약한 학습기들을 생성 후 이를 선형결합하여 최종 학습기를 만듦 -모델 구성 과정에서 독립변수를 임의로 추출하고 추출된 변수들 내에서 최적의 분할을 만들어 나가는 방법 -모든 모델은 서로 다른 독립변수를 학습하므로 Tree Correlation을 방지할 수 있음 *Tree Correlation: 개별 트리들 간의 상관관계. 낮으면 서로 다른 패턴/정보 사용하므로 앙상블 모델 성능이 향상됨 -Hyper Parameter(초매개변수) 조정 시간 단축 -R에서는 randomForest 패키지 사용 |
| 비교 | 배깅 | 부스팅 |
| 특징 | 병렬적 앙상블 채택 (각 모델은 서로 독립적) |
연속적 앙상블 채택 (이전 모델의 오차를 고려) |
| 목적 | 분산 감소 | 편향 감소 |
| 적합한 상황 | 높은 분산, 낮은 편향 | 낮은 분산, 높은 편향 |
| 대표 알고리즘 | Random Forest | XGBoost |
| 샘플링 | 랜덤 샘플링 | 오차의 가중치를 반영한 랜덤 샘플링 |
랜덤포레스트
-서로 독립일수록 결합 성능이 좋으므로 난수를 사용해 독립성 확보: 가장 좋은 k개의 후보 질문 중 랜덤하게 질문을 노드에 부여
-분류모델 - voting / 회귀모델 - 평균(average) 값을 출력
-변수 제거 없이 실행되어 정확도가 좋으나 해석이 어려움
평가방법)
| 평균 절대 백분율 오차 (Mean Absolute Percentage Error) |
MAPE |
| 평균 제곱근 오차 (Root Mean Square Error) |
RMSE |
| 평균 절대 오차 (Mean Absolute Error) |
MAE |
7) 모형 평가
-Confusion Matrix (오차 행렬 / 혼동행렬): 분류기의 성능을 평가하는 방법 중 하나.
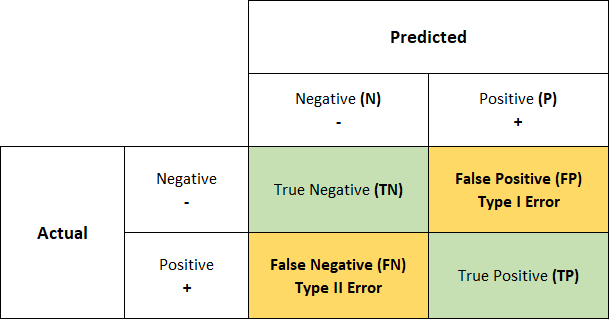
*정답: True / False
*예측 결과: Positive / Negative
*FP: False를 Positive로 예측. 음성 클래스를 양성 클래스로 예측. Type-I-Error = false alarm
*FN: True를 Negative로 예측. 양성 클래스를 음성 클래스로 예측. Type-II-Error = missed detection
혼동행렬을 이용한 분류 모델의 평가 지표
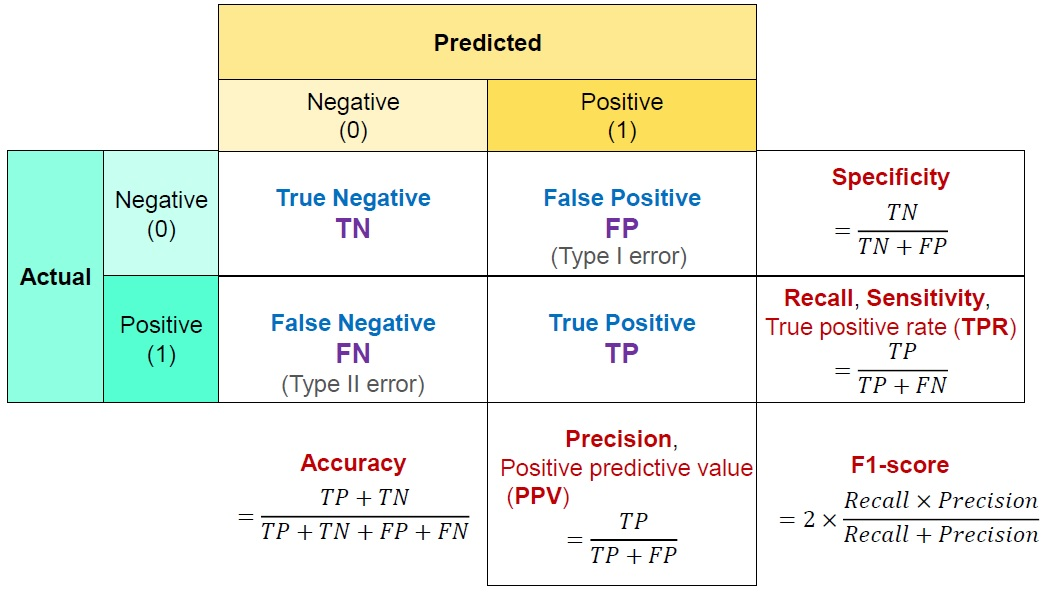
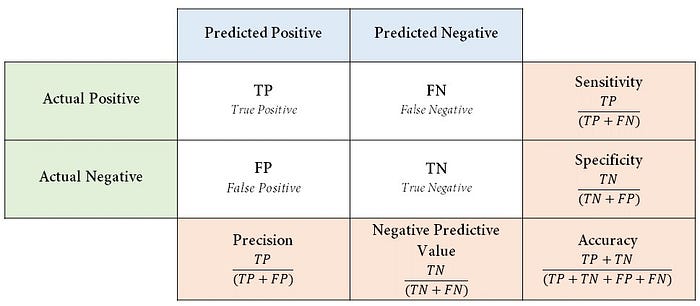
**1종 오류와 2종 오류
| 암 치료제 개발에 따른 약효 확인을 위한 검정 귀무가설: 암 치료제가 효과가 없다 대립가설: 암 치료제가 효과가 있다 |
|
| 1종 오류: 귀무가설이 참인데 기각할 때 발생하는 오류 | 2종 오류: 귀무가설이 거짓인데 기각하지 않았을 때 발생하는 오류 |
| 암 치료제가 실제로 효과가 없는데 효과가 있다고 판단하는 오류 | 암 치료제가 실제로 효과가 있지만 효과가 없다고 판단하는 오류 |
| Accuracy: 정확도 | 제대로 분류한 데이터 수 / 전체 데이터 수 전체 데이터 중 정확히 분류한 데이터의 비율. 오차율(Error Rate): 전체 데이터 중 잘못 분류한 데이터의 비율. Accuracy = 1 - Error Rate -시스템의 결과가 참값에 얼마나 가까운지 나타내는 척도 |
| Recall : 재현율 | 실제 true인 것 중 모델이 True라고 예측한 것의 비율 sensitivity(민감도), hit rate, True Positive Rate (TPR)이라고 함. |
| Precision: 정밀도 |
모델이 True라 분류한 것 중 실제 True인 것의 비율 -Positive Predictive Value (양성 예측도)라고 한다. -시스템이 얼마나 일관된 값을 출력하는지를 나타내는 척도 |
| Specificity: 특이도 | 실제 음성인 데이터 중 음성으로 올바르게 예측한 비율 True Negative Rate (TNR) |
| Fall-Out: FP Rate, 거짓 긍정률 | FP / (TN + FP) = 양성으로 잘못 분류한 음성 데이터 수 / 전체 음성 데이터 수 1 - Specificity(특이도) ROC 커브 그리는데 사용 |
| F1 Score | 2 * ((정밀도*재현율) / (정밀도 + 재현율) Precision과 Recall은 트레이드오프 (trade-off) 관계에 있으므로, 둘 중 어느 한 쪽에만 치우지지 않고 모두를 반영하여 분류기의 성능을 측정하기 위해 사용 -정밀도와 재현율의 조화평균 -정밀도와 재현율이 같을 때 가장 높다. -0~1 사이의 값, 높을수록 좋은 모델 |
*정밀도와 재현율의 관계
Threshold: 임계값.
-분류기는 각 샘플의 점수를 계산하여 정해진 임계값보다 크면 이를 양성 클래스로 분류함 / 작으면 음성 클래스로 분류
-따라서 정밀도와 재현율은 서로 반비례로서 trade-off 관계에 있다.
-정밀도는 모델의 입장에서 평가하는 지표 / 재현율은 데이터의 입장에서 평가하는 지표
-Threshold를 높이면 -> 음성 클래스를 양성 클래스로 오분류하는 경우가 감소, 정밀도 좋아짐, 재현율 감소
-Threshold를 낮추면(마이너스 무한대) -> 모든 샘플을 양성 클래스로 분류할 것, 이 때 재현율은 100%가 되지만 정밀도는 최소가 된다.
PR곡선: 재현율에 대한 정밀도 곡선 (Precision-Recall Curve)를 그려 정밀도가 급격하게 감소하기 시작하는 하강점 직전을 정밀도/재현율 트레이드 오프로 선택하는 것이 좋음.
*ROC Curve
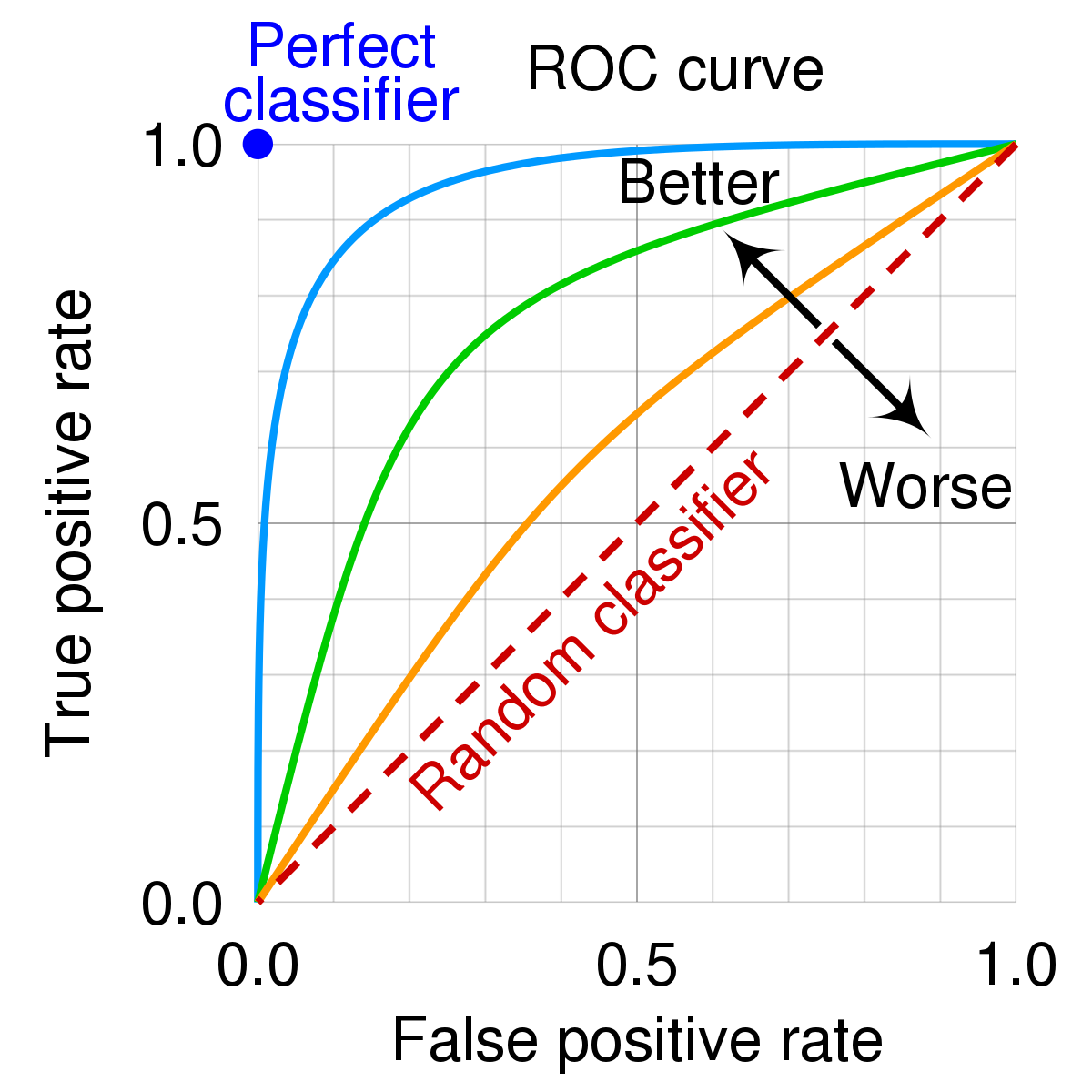
*FPR: 1 - Specificity
세로축 = Recall 값
TPR과 Recall 역시 trade-off 관계. (?????오류 같은디
FPR은 작을수록 좋고, TPR은 클수록 좋음
Threshold을 높이면 FPR 감소 / TPR도 함께 감소.
이상적인 분류기는 FPR이 0, TPR이 1. ROC 곡선의 좌측 상단에 위치함
8) 교차 검증
-모델에 대한 일반화 오차에 대해 신뢰할 만한 추정치를 구하기 위해 훈련 데이터 및 평가 데이터를 기반으로 하는 검증 기법을 의미함
| 홀드 아웃 교차 검증 (Holdout Cross Validation) |
-일반적으로 아는 방식 -전체 데이터를 비복원추출 방법으로 이용하여 랜덤하게 학습 데이터와 테스트 데이터를 나눠 검증 (8:2 , 6:2:2) |
-데이터 손실 발생: 테스트 데이터는 학습에 사용할 수 없어서 |
| K-Fold Cross Validation | -데이터 집합을 무작위로 동일 크기를 갖는 K개의 부분집합으로 나누고, 그 중 1개의 집합을 테스트 데이터로 사용 / 나머지 K-1개는 학습 데이터로 선정 -K번 반복수행 -각 폴드에 대한 결과를 평균으로 분석 |
|
| Leave-One-Out-Cross Validation (LOOCV) |
-전체 데이터 N개에서 1개의 샘플만을 평가 데이터에 사용 / 나머지 N-1개는 훈련 데이터로 사용하는 과정을 N번 반복 -K-Fold와 같은 방식 (K = N) |
-작은 크기의 데이터에 사용하기 좋음 |
| LpOCV (Leave-p-Out-Cross Validation) | -LOOCV에서 1개의 샘플이 아닌 p개의 샘플을 테스트에 사용하는 기법 | -계산시간 너무 오래 걸림 |
| 부트스트랩 (Bootstrap) |
-주어진자료에서 단순 랜덤 복원추출 방법을 활용해 동일한 크기의 표본을 여러 개 생성하는 샘플링 방법 -무작의 복원추출 -전체 데이터에서 중복을 허용해 데이터 크기만큼 샘플을 추출하고 이를 훈련데이터로 씀 -표본을 다시 추출 -중복 추출 허용 |
- 데이터셋 분포가 고르지 않을 때 사용 - 과적합을 줄이는데 도움이 됨 |
| 계층별 k-겹 교차 검증 | -각 폴드가 가지는 레이블의 분포가 유사하도록 폴드를 추출해 교차 검증을 실시 | -주로 불균형 데이터를 분석 |
section 2. 군집분석
-clustering
-데이터 간 유사도(주로 거리) 이용해 분석 대상을 몇 개의 군집으로 분류함 / 비지도 학습이므로 Y(종속변수) 없음
-변수의 측정 단위와 관계없이 그 차이에 따라 일정하게 거리를 측정하기 때문에 변수를 표준화/정규화 해서 사용해야함
<종류>
계층적 군집화 (Hierarchical Clustering)
-덴드로그램을 생각하자
각 관측치를 하나의 최초 군집으로 지정한 후, 한 번에 두 개씩 하나의 군집으로 만들어, 모든 군집들이 하나의 군집이 될 때까지 결합해 나가는 방식
| 최단 연결법 | 최장 연결법 | 평균 연결법 | 와드 연결법 |
| 거리행렬에서 가장 가까운 데이터를 묶어서 군집 형성 고립된 군집을 찾는데 중점을 둔 방법 |
거리가 먼 데이터나 군집을 묶어서 형성 (거리의 최대값) 군집들으 내부 응집성에 중점을 둔 방법 |
최단 연결법과 동일 / 거리를 구할 때 평균을 사용 |
군집 내 편차들의 제곱합을 고려 크기가 비슷한 군집끼리 병합하게 되는 경향 |
*군집의 거리 계산
1. 유클리드 거리 : 일반적인 방법. 두 점 사이의 거리 구하기. L2 distance
2. 맨해튼 거리: L1 Distance. 두 점의 각 성분별 차의 절대값으로 거리를 구한다.
3. 자카드 거리: 자카드 지수- 두 집합의 교집합을 합집합으로 나눈 값 / 자카드 거리 = 1 - 자카드 지수
4. 코사인 거리: 코사인 유사도 - 두 벡터가 이루는 각도의 코사인 값을 이용해 측정된 거리 / 코사인 거리 = 1 - 코사인 유사도
기타) 민코프스키 거리(맨해튼, 유클리드 한 번에) / 표준화 거리(표준편차로 유클리드 거리 계산) / 마할라노비스 거리(변수의 표준화 및 상관성을 함께 고려, 통계적 거리) / 체비셰프 거리 (두 점의 x좌표 차 / y 좌표 차 중 큰 값을 갖는 거리) / 캔버라 거리(각 차원의 값의 차이를 절대값으로...어쩌굴...)
| 변수 유형 | 거리 |
| 연속형 범수 | 유클리드, 맨해튼, 민코프스키, 표준화, 마할라노비스, 쳬비셰프, 코사인 |
| 범주형 변수 | 캔버라, 자카드 |
| 속성 | 거리 |
| 수학적 거리 | 유클리드, 맨해튼, 민코프스키, 체비셰프 |
| 통계적 거리 | 표준화, 마할라노비스, 캔버라 |
비계층적 군집화 (Partitional Clustering)
군집수 k를 지정한 후,관측치들을 무작위로 k개의 집단으로 분할한 후 centroid(중심점)을 수정해나가며 집단을 재분류 (재분류는 평균값, 최빈값 등을 기준으로 진행)
| K-means 군집화 | DBSCAN (Density-Based) | 혼합분포 군집화 | PAM | Fuzzy |
| 데이터를 k개의 군집으로 묶음 거리 계산을 통해 진행 연속형 변수에 활용 k개의 초기 중심점은 임의로 선택 |
Density-Based Spatial Clustering of Applications with Noise 밀도 기반. 밀집된 곳을 하나의 군집으로 인식 군집의 개수를 미리 정의X 노이즈 데이터는 군집에서 제외 |
Mixture Distribution Clustering 여러가지 분포를 확률적으로 선형 결합한 분포 각 데이터가 여러 개의 다른 분포를 따르는 것을 의미 -각 데이터가 혼합 분포 중 어느 모형으로 나왔을 확률이 높은지에 따라 군집을 분류 -모수와 함께 가중치를 자료로부터 추정 -> EM(Expectation-Maximization 기대값 최대화) 알고리즘 사용 |
Partitioning Around Medoids -K-means와 유사한데, 중앙값(medoid)을 이용하여 데이터를 군집화 -이상치에 강건한 특징 |
퍼지이론에 기반하여... 경계가 모호한 경우에도 군집화 수행 |
SOM (Self Organizing Map / 자기조직화지도)
비지도학습 / 순전파 / 신경망
고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬하여 지도 형태로 형상화.
차원 축소와 군집화를 동시에 수행하는 분류기법으로 사용됨
경쟁 / 협력 / 적응 단계로 진행됨. (입력층/경쟁층=출력층 존재, 경쟁 학습 진행)
시각적으로 이해하기 편해 / 패턴 발견, 이미지 분석 등에서 뛰어난 성능을 나타냄
유전 알고리즘 (Genetic Algorithm, GA)
생명의 진화를 모방하여 최적해(Optimal Solution)를 구하는 알고리즘. 최적화가 필요한 문제의 해결책을 메커니즘(자연선택/돌연변이)을 통해 점진적으로 진화시키는 방법
Section 3. 연관분석
-대량의 데이터에 숨겨진 항목간의 연관규칙을 찾아내는 분석 기법
-장바구니 분석(market basket analysis): 장바구니에 무엇이 같이 들어 있는지에 대해 분석하는 것임
ex) 맥주를 구매한 고객은 땅콩을 구매할 확률이 높다. <<와 같은 구매 패턴을 분석하여 의미있는 규칙을 찾아내기
-최소 지지도, 최소 신뢰도를 적정 수준으로 설정하는 것이 중요함.
-R에서는 inspect 명령어를 사용
<특징>
- 비지도 학습에 의한 패턴 분석
- 평가도구: 지지도, 신뢰도, 향상도
- 범주 구성
- 추천, 패키지 상품 판매 및 기획 등 마케팅 분야에 활용
연관 분석 알고리즘
| Apriori 알고리즘 | FP-Growth 알고리즘 |
| -지지도 및 신뢰도를 적정하게 설정하여 빈발 아이템 항목을 판별하고, 이에 대해서만 연관규칙을 찾아 계산 복잡도를 감소 1. 최소 지지도 설정 2. 개별품목 중 최소 지지도를 넘는 모든 품목을 찾기 3. 찾은 개별 품목만을 이용하여 최소 지지도를 넘는 두 가지 품목 집합 찾기 4. 찾은 품목 집합을 결합해 최소 지지도를 넘는 세 가지 품목 집합 찾기 5. 반복적으로 수행하여 최소 지지도가 넘는 빈발품목 찾기 |
-상향식 -지지도가 낮은 품목부터 높은 품목 순으로 올라가면서 빈도수가 높은 아이템 집합을 생성하는 상향식 알고리즘 -Apriori보다 속도가 빠르고, 연산 비용이 저렴 |
척도
| 지지도(Support) | 신뢰도(Confidence) | 향상도(Lift) |
| -전체 거래 중 두 개의 품목 A,B,가 동시에 포함되어 거래된 비율 -지지도가 높다 = 두 개의 아이템이 함께 잘 팔림 |
-항목 A를 포함한 거래 중 항목 A,B가 함께 포함되어 거래된 비율 -연관성의 정도 파악 가능 -조건부 확률 -신뢰도(A→B) = P(B|A) -신뢰도(B→A) = P(A|B) |
-A가 주어지지 않았을 때 품목 B의 구매 확률에 비해, A가 주어졌을 때의 품목 B의 구매 확률의 증가 비율 -향상도(A→B) = 신뢰도(A→B) / P(B) = P(A∩B) / P(A)P(B) -A와 B 사이에 아무런 상호관계가 없으면 향상도는 1, 향상도가 1보다 클수록 연관성이 높음 |
| P(A∩B) = A와 B가 동시에 포함된 거래 수 / 전체 거래 수 | P(A∩B) / P(A) = A와 B가 동시에 포함된 거래 수 / A가 포함된 거래 수 | Lift > 1 : 품목간 상호 양의 관계 (A를 사면 B도 산다) Lift = 1 : 품목간 상호 독립적인 관계 0 < Lift < 1 : 품목간 상호 음의 상관관계 |
<관련 R 코드>
- 향상도 - arules 패키지
- inspect()함수: 객체에 포함된 규칙이나 아이템 집합 등을 보여줌
참고)
'ADsP 데이터분석준전문가 자격증 공부' 카테고리의 다른 글
| [BDA x 영진닷컴] BDA 스터디: 5주차 (1) | 2024.05.06 |
|---|---|
| ADsP PART 2 기출 오답 (0) | 2024.04.23 |
| [BDA x 영진닷컴] BDA 스터디: 4주차 / PART 2 개념 정리 (1) | 2024.04.22 |
| [BDA x 영진닷컴] BDA 스터디: 3주차 (0) | 2024.04.15 |
| [BDA x 영진닷컴] ADsP 스터디: 1주차 (1) | 2024.04.01 |


